


What's Right for Your Study?
A university-based clinical research team is concluding a five-year longitudinal study evaluating trauma-informed therapeutic interventions for adolescent patient populations. The team has gathered hundreds of hours of recorded qualitative interviews. A graduate research assistant, tasked with coding the qualitative data, notices a pattern: a patient’s description of a traumatic event contains extensive pauses, stutters, and whispered filler words. In the initial coding pass, one researcher codes these as indications of profound psychological resistance and emotional distress. However, a second researcher, reviewing a text-only transcript prepared by an automated utility, codes the same interaction as a coherent, calm narrative with no signs of distress. The automated utility had stripped away all pauses, filler words, and vocal tremors to improve readability.
This scenario represents a classic methodological conflict. The choice of transcription style is not a minor formatting task; it is a critical methodological decision that directly influences qualitative data coding, inter-coder reliability, and regulatory alignment. For principal investigators, graduate students, and compliance officers, selecting the incorrect transcription methodology can introduce systemic researcher bias, alter the analytical outcomes of a study, and even raise concerns during Institutional Review Board (IRB) or peer reviews.
This comprehensive guide analyzes the functional differences between verbatim transcription and clean verbatim transcription. It evaluates their methodological implications, regulatory parameters, and technical execution to assist you in selecting the precise transcription standard required for your research design.
Foundations of Qualitative Transcription Methodology
In qualitative inquiry, transcription serves as the primary conduit between raw oral speech and systematic textual analysis. It is not a passive or neutral clerical task; rather, it is an interpretive act where the researcher makes deliberate decisions about how spoken language is represented on the page. To build a rigorous analytical framework, we must begin by clarifying core terminology.
Defining Verbatim Transcription
To understand the utility of this method, one must ask: what is verbatim transcription? By definition, it is the exact, word-for-word conversion of spoken language into written text, capturing every acoustic event precisely as it occurs on the audio recording. This approach requires the transcriber to document not only the literal words spoken but also the non-verbal behaviors, vocal inflections, stutters, and environmental sounds that accompany the speech.
The standard verbatim transcription definition centers on absolute fidelity to the original sound file. Under this paradigm, the transcriptionist does not correct grammatical errors, reorganize sentence structures, or omit repetitive filler words. The operational verbatim transcription meaning is simple: compile an unvarnished, objective record of the interaction, preserving the linguistic raw material in its purest form.
The Verbatim vs. Non-Verbatim Dichotomy
When evaluating verbatim vs non-verbatim transcription, researchers are choosing between two distinct epistemological stances. To fully appreciate this choice, we must analyze what is non verbatim transcription.
Non-verbatim transcription, often referred to as edited, summarized, or paraphrased transcription, does not attempt to capture the exact words of the speaker. Instead, it synthesizes the spoken content into a summarized narrative or a series of bullet points that represent the core ideas. While this approach is sometimes used for brief corporate meetings, administrative notes, or preliminary project briefings, it is generally unsuitable for academic, clinical, or legal research.
Non-verbatim methods introduce immediate subjectivity, as the transcriptionist must decide which details are trivial enough to discard and which are important enough to keep. This pre-analysis bypasses the formal coding process, threatening the validity of the qualitative study.
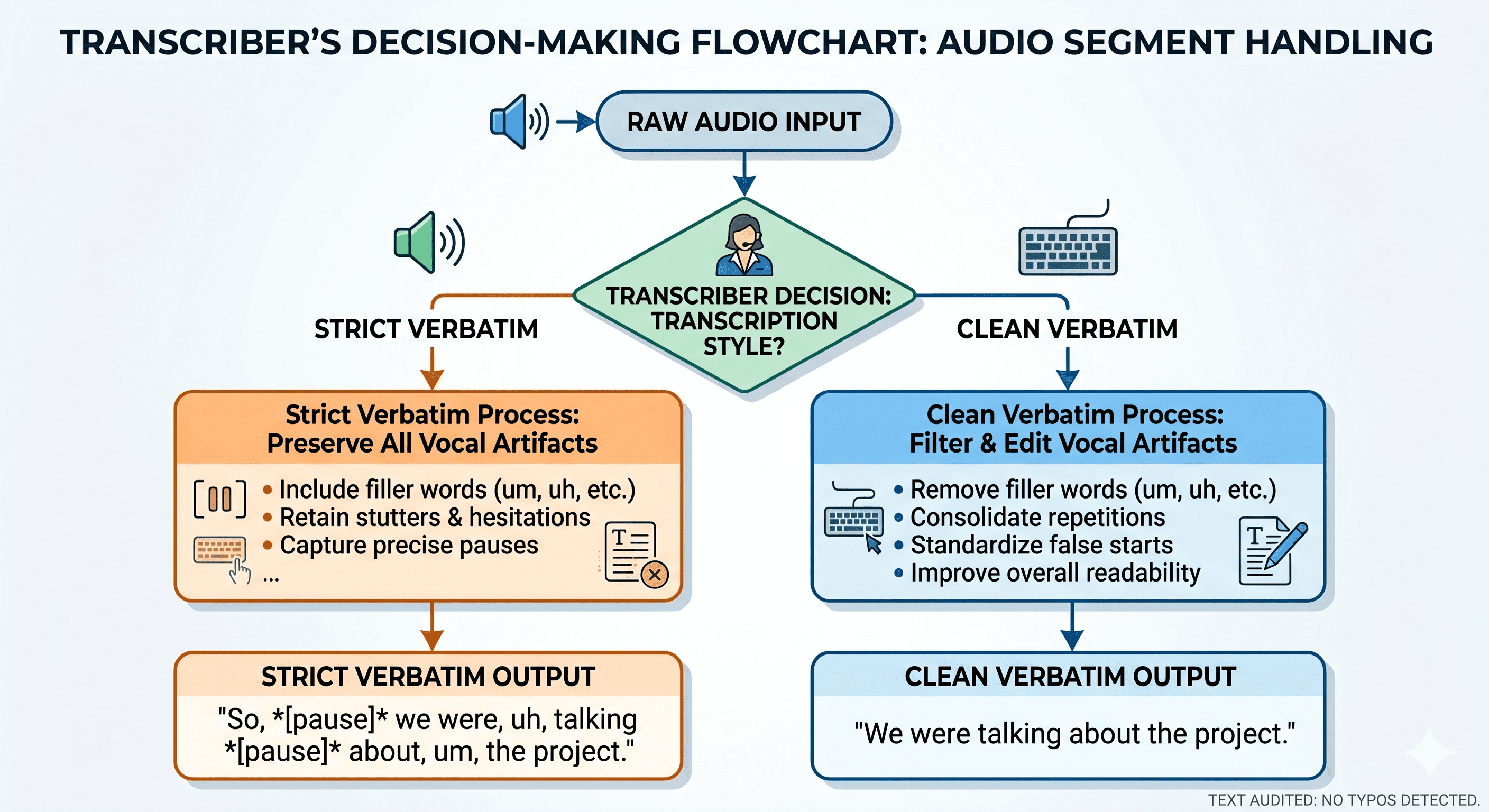
Strict Verbatim Transcription
Within the verbatim spectrum, there are varying levels of detail. The most rigorous and exhaustive standard is strict verbatim transcription (also called full or orthographic verbatim). This method documents every vocal event with micro-level precision, including:
Exact durations of silence (e.g., noting a pause as
[pause 1.5s]or using specialized notation like ellipses);Non-verbal vocalizations such as laughter, sighs, crying, whispering, throat-clearing, or coughing;
Involuntary speech patterns, including stutters, filler words ("um," "uh," "ah"), and false starts where a speaker abandons a sentence mid-thought;
Overlapping dialogue, where multiple speakers talk simultaneously, and ambient environmental noises (such as telephone rings, door clicks, or background chatter).
This level of detail is necessary for specific qualitative methodologies where the structure of the delivery is just as informative as the content itself.
The Nuances of Clean Verbatim Transcription
While preserving every acoustic event provides a highly detailed record, it can also create documents that are exceptionally difficult to read and analyze. A single page of strict verbatim text can be cluttered with "ums," "ahs," and fragmented sentences, which increases the cognitive load on the qualitative coder. This challenge has driven the widespread adoption of clean verbatim transcription.
Defining Clean Verbatim Transcription
To evaluate whether this approach suits your research, you must understand the clean verbatim transcription definition. In qualitative research, what is clean verbatim transcription? It is an approach that preserves the exact words spoken by the participant but systematically removes speech disfluencies, fillers, stutters, false starts, and non-verbal cues that do not contribute to the semantic meaning of the statement.
To clarify what does clean verbatim transcription mean in practice, consider the primary edits a transcriber makes under this standard:
Omission of Fillers: Words like "um," "uh," "ah," "like," "you know," and "so" are deleted if they are used simply as conversational placeholders.
Removal of Stutters and Repetitions: Involuntary sound repetitions (e.g., "I-I-I went to the...") are consolidated into a single, clean phrase ("I went to the...").
Correction of False Starts: If a speaker begins a sentence, immediately aborts it, and restarts with a clearer phrasing, the aborted start is removed, provided it does not contain a significant shift in meaning.
Exclusion of Non-Verbal and Ambient Sounds: Whispers, background noises, laughter, and sighs are omitted from the text unless they are critical to understanding the emotional context of a specific response.
Intelligent Verbatim Transcription
A closely related variation is intelligent verbatim transcription (sometimes referred to as clean read or polished transcription). While clean verbatim preserves the speaker's exact vocabulary, slang, and non-standard grammar, intelligent verbatim takes the cleanup process a step further by correcting minor grammatical errors, standardizing colloquial slang (e.g., changing "gonna" to "going to" or "wanna" to "want to"), and organizing rambling sentences into more readable structures.
While this method produces highly polished, publication-ready text, it must be used with caution in formal research. Altering a participant's natural grammar or slang can inadvertently strip away their cultural voice, socioeconomic indicators, or regional dialect. This risk must be carefully managed to avoid homogenizing the qualitative data.
To keep these edits consistent across a project, research teams must establish explicit verbatim transcription rules. These rules act as a project-specific standard operating procedure (SOP), defining exactly which filler words should be removed, how to handle regional slang, and how to format unavoidable non-verbal cues. Without clear, documented rules, collaborative research teams risk introducing transcription variance that can undermine the reliability of their qualitative coding.
Side-by-Side Comparison of Transcription Standards
To help you choose the best approach for your study, the following table compares strict verbatim, clean verbatim, intelligent verbatim, and non-verbatim transcription across key linguistic and analytical criteria.
Feature / Criteria | Strict Verbatim Transcription | Clean Verbatim Transcription | Intelligent Verbatim Transcription | Non-Verbatim Transcription |
Primary Objective | Captures the absolute acoustic reality of the recording. | Balance legibility with complete semantic accuracy. | Create a polished, grammatically correct text. | Summarize or paraphrase core concepts and ideas. |
Linguistic Fillers (e.g., "um", "uh") | Preserved: Every filler is transcribed exactly as spoken. | Removed: Omitted entirely to clean up the sentence flow. | Removed: Omitted entirely. | Removed: Omitted entirely. |
Stutters & Repetitions | Preserved: Documented exactly (e.g., "I-I-I think..."). | Removed: Consolidated into a single phrase. | Removed: Consolidated and polished. | Removed: Omitted entirely. |
Colloquial Slang (e.g., "gonna", "y'all") | Preserved: Transcribed phonetically to match pronunciation. | Preserved: Exact words are kept, preserving the speaker's voice. | Standardized: Changed to standard formal English (e.g., "going to"). | Standardized: Translated into formal, summarized prose. |
Grammatical Errors (e.g., "they was") | Preserved: Uncorrected to maintain linguistic authenticity. | Preserved: Left uncorrected to capture natural speech patterns. | Corrected: Adjusted to match formal grammatical rules. | Corrected: Written using standard formal prose. |
Non-Verbal Cues (e.g., sighs, laughter) | Preserved: Documented with timestamps or descriptive tags. | Removed: Omitted, unless highly critical to the emotional context. | Removed: Omitted entirely. | Removed: Omitted entirely. |
Best Academic Use Cases | Conversation Analysis, Discourse Analysis, Sociolinguistics. | Thematic Analysis, Grounded Theory, Phenomenological Studies. | Focus group reports, market research, stakeholder presentations. | Executive summaries, administrative briefs, preliminary reviews. |
Methodological Risks | High cognitive load during coding; difficult to read. | Potential loss of subtle emotional or psychological cues. | Risk of altering the participant's authentic cultural voice. | High risk of subjective researcher bias and loss of primary data. |
Methodological Impacts on Qualitative Research Paradigms
The choice between strict verbatim and clean verbatim is not simply a matter of convenience; it is a foundational research decision. Different qualitative frameworks have specific requirements regarding the level of detail needed in a transcript.
Conversation Analysis and Discourse Analysis
In Conversation Analysis (CA) and Discourse Analysis (DA), the structure of the delivery is just as important as the words spoken. CA examines the structural organization of social interaction, which means the researcher must analyze the exact timing of turn-taking, pauses, and speech overlap.
For these methodologies, strict verbatim transcription is an absolute necessity. Researchers in these fields frequently use specialized notation systems, such as the Jefferson Transcription System, to document micro-pauses down to the tenth of a second, vocal volume shifts, latching speech (where there is no gap between speakers), and changes in pitch.
For example, consider how a micro-pause can change the interpretation of a response:
Strict Verbatim:
Interviewer: "Did you feel safe during the treatment?"
Participant:[pause 2.4s]"Yes...[sigh]... I suppose so."Clean Verbatim:
Interviewer: "Did you feel safe during the treatment?"
Participant: "Yes, I suppose so."
In a clean verbatim transcript, the 2.4-second delay, the sigh, and the initial hesitation are completely lost. For a conversation analyst or a clinical psychologist, that long pause and heavy sigh are critical indicators of hesitation, doubt, or underlying trauma. Converting this exchange to clean verbatim removes the subtle behavioral evidence, which could lead to an inaccurate assessment of the participant's comfort level.
Grounded Theory and Interpretative Phenomenological Analysis (IPA)
For Grounded Theory (GT) and Interpretative Phenomenological Analysis (IPA), the analytical focus is typically on understanding lived experiences and identifying emerging themes across a dataset.
In these research designs, clean verbatim transcription is often preferred. It allows the researcher to analyze large volumes of text without being slowed down by phonetic details, stutters, or filler words that do not alter the core meaning of the participant's statements. However, even within thematic frameworks, researchers must proceed with caution.
"In my decades of managing qualitative field studies, I've observed how easy it is to sanitize a participant's voice in the interest of quick coding. When transcribing interviews with rural patients describing chronic pain, their hesitant pauses and local idioms are not 'noise'—they are the core of the data. If a graduate assistant cleans up a phrase like, 'I, uh, well, it... it hurts kinda bad, ya know?' into a simple 'It hurts,' they have not just transcribed; they have interpreted. You must establish clear boundaries before anyone presses 'Record'."
— A Principal Investigator's Perspective
Thematic Analysis (TA)
In Thematic Analysis, particularly using the frameworks established by Braun and Clarke, the primary goal is to identify and organize semantic themes across interviews. Clean verbatim is the standard of choice here. It keeps the data highly legible, making it easier to code and extract clear, direct quotations for academic papers or clinical reports.
When managing large, multi-site longitudinal trials, using an external verbatim transcription service or a professional verbatim transcription company is a common way to maintain consistency. For projects with complex data or multiple languages, choosing institutional-grade transcription and localization through a partner like Ant helps ensure that regional dialects, technical terminology, and semantic nuances are preserved accurately, reducing the risk of systematic errors across the dataset.
Legal, Regulatory, and IRB Compliance Nuances
Research involving human subjects carries significant ethical and regulatory responsibilities. Compliance officers and principal investigators must ensure that their transcription workflows align with Institutional Review Board (IRB) requirements, HIPAA guidelines for protected health information, and data protection standards like GDPR.
Legal Verbatim Transcription Constraints
In legal contexts, such as depositions, witness statements, or regulatory investigations, legal verbatim transcription is the mandatory standard. In these situations, the transcript must be an exact, legally defensible record of the proceedings. Even a minor edit—such as removing a double negative or correcting a grammatical slip—can change how a statement is interpreted in court.
Within academic research, similar standards apply when investigating sensitive topics like illicit behavior, corporate non-compliance, or clinical trials involving adverse drug events. If a transcript is ever subpoenaed or subjected to a regulatory audit, having a strict verbatim record ensures that the data is represented accurately and without editorial adjustments.
For authoritative federal guidelines on qualitative data archiving, human subject protections, and regulatory standards, consult the National Institutes of Health (NIH) Office of Extramural Research at https://grants.nih.gov/ or the U.S. Department of Health and Human Services (HHS) Office for Human Research Protections at https://www.hhs.gov/ohrp/.
Data De-Identification and Pseudonymization
One of the most critical steps in qualitative transcription is protecting participant anonymity. While transcribers are often tasked with removing personally identifiable information (PII)—such as specific names, street addresses, or employers—they must do so without altering the structure of the speech.
This process can be challenging when working with strict verbatim files. If a participant speaks in a highly distinctive way or uses highly specific regional slang, preserving those exact patterns can make them identifiable to a local audience, even after names and dates have been removed. Conversely, using automated consumer-grade AI tools to clean up transcripts poses significant privacy risks, as many free or low-cost online tools use user data to train their models. This can lead to a severe breach of participant confidentiality.
To mitigate these risks, research institutions should work with a secure, compliant verbatim transcription service that sign legally binding Business Associate Agreements (BAAs) and process data on encrypted, high-security servers. Using institutional-grade partners ensures that you maintain high analytical standards while staying fully compliant with IRB and federal data protection regulations.
Advanced Protocols
To help your research team maintain high methodological standards, this section outlines step-by-step protocols for managing, executing, and verifying qualitative transcription.
Step 1: Recording Calibration and Environment Setup
The accuracy of any transcript depends heavily on the quality of the raw audio.
Equipment Selection: Use high-quality, omnidirectional boundary microphones for focus groups, and directional lapel microphones for one-on-one interviews.
Acoustic Mitigation: Conduct interviews in quiet, carpeted rooms to reduce echo, and place the recording device on a stable surface away from ventilation fans, laptops, or mobile devices.
Turn-Taking Rules: Establish clear guidelines for focus groups, requiring participants to speak one at a time and state their names or speaker codes before talking to assist the transcriber with identification.
Step 2: Developing the Project Style Guide and Rules
Before starting, create a comprehensive style manual that details your team's verbatim transcription rules. This guide should answer several key questions:
How should brief pauses (under 2 seconds) versus long pauses (over 2 seconds) be documented?
What are the specific bracketed tags used for non-verbal cues (e.g.,
[laughter],[sigh],[whispering])?How should unintelligible words or overlapping speech be labeled (e.g., using
[unintelligible 00:12:34]with a timestamp)?Under what circumstances can a false start be omitted, and when must it be preserved?
Step 3: The Multi-Pass Quality Assurance Workflow
To maintain high accuracy, avoid relying on a single transcription pass. Instead, use a structured multi-pass workflow:
Raw Audio File ➔ PASS 1: Transcription (Drafting the initial text)
➔ PASS 2: Verification (Synchronizing and correcting errors)
➔ PASS 3: De-Identification (Redacting PII and finalizing formatting)
Pass 1: Text Capture: The transcriber drafts the initial text, focusing on capturing the spoken words accurately.
Pass 2: Audio Verification: A reviewer listens to the audio while reading the draft transcript, correcting any misheard words, adjusting speaker tags, and verifying timestamps.
Pass 3: De-Identification & Compliance: A third review is conducted to redact sensitive identifiers (e.g., replacing "Dr. Smith at Mercy Hospital" with [Physician 1 at Hospital A]) and ensure the formatting matches your project's style guide.
Transcription Examples
To help you choose the right approach for your study, review the following examples demonstrating how different transcription methods handle the same audio segment.
Scenario: Clinical Trial Interview
Context: A patient is describing an adverse drug reaction during a clinical trial.
Strict Verbatim Transcription Example
Interviewer: "Can you... um... walk me through what happened next?"
Participant: "Well...[pause 1.8s]... I woke up at, like, three in the morning. And I felt...[gasp]... I-I felt this incredibly sharp pain right here in my chest. It was, like, y'all have got to understand, I thought I was... I was having a heart attack. I-I couldn't breathe.[cough]... It was terrifying, you know?"
Clean Verbatim Transcription Example
Interviewer: "Can you walk me through what happened next?"
Participant: "Well, I woke up at three in the morning. And I felt this incredibly sharp pain right here in my chest. It was, y'all have got to understand, I thought I was having a heart attack. I couldn't breathe. It was terrifying."
Intelligent Verbatim Transcription Example
Interviewer: "Can you walk me through what happened next?"
Participant: "Well, I woke up at three in the morning. And I felt this incredibly sharp pain right here in my chest. You have got to understand, I thought I was having a heart attack. I could not breathe. It was terrifying."
Selecting the Right Approach for Your Study
To determine how to verbatim transcribe your dataset effectively, weigh your study's methodological requirements against your available resources.
If your research relies on analyzing the mechanics of speech, such as evaluating cognitive load, identifying emotional hesitation, or conducting conversation analysis, strict verbatim transcription is the correct choice. While it requires more time to transcribe and code, it preserves the complete, unaltered behavioral data.
If your research is focused on identifying semantic themes, patterns, or conceptual connections across many interviews, clean verbatim transcription is generally the most efficient and reliable standard. It removes speech disfluencies and fillers, keeping the text highly legible and making coding and direct quotation straightforward
When in-house resources are limited or your project demands strict data protection and regulatory compliance, partnering with a professional verbatim transcription company can help you manage risk. Ant provides secure, compliant institutional-grade transcription and localization to support your research methodology, keep your data protected, and ensure your project stands up to rigorous academic and peer reviews.
For detailed standards on reporting qualitative research, including transcription documentation guidelines, review the Consolidated Criteria for Reporting Qualitative Research (COREQ) and the Standards for Reporting Qualitative Research (SRQR) via the EQUATOR Network at https://www.equator-network.org/.
